AI On Premise - Part 2 Practice
Feed all your sensitive data into an AI knowledge base, that can answer your questions? No problem - as long it is running in house. Weaviate for AI-Powered Knowledge Management On Premise.


Feed all your sensitive data into an AI knowledge base, that can answer your questions? No problem - as long it is running in house.
opensight.ch - roman hüsler
The LLMs are the latest rage, a big step in digitalization and a disruptive technology. It is not without reason that many companies ask themselves how can I use the technology in my company. Companies' sensitive data usually cannot be easily sent to a cloud-based AI such as chatgpt for evaluation. Companies therefore often ask themselves how AI solutions can be used internally and securely.
AI can be used for a variety of tasks. Today, in this blog, we don't focus on LLM's though (let us know when you are interested in this topic) but on a similar field of AI - natural language processing (NLP) and creation of an "on-premise-ai-powered" knowledge base. You can plug in your local Knowledge Base (i.e. confluence) and create a question-answer ai machine.
Today we take a look at Weaviate, an AI-powered vector search engine that works with pre-trained language models and can be operated internally / on premise.
opensight.ch - roman hüsler
Like many IT technicians, me as well I am acquiring knowledge in this field. I assume that many readers of this blog are in a similar position and that is how they found this blog post. This means you don't have to be an AI specialist to follow this blog post.
Content
The Big Goal - AI On Premise
Let's set the goal for this blog series. We would like to achieve:
- AI on premise
Have an AI that can operate locally on premise. - Knowledge Base
It should be able to interact with text data (i.e. a knowledge base) - Question, Answer
I like to be able to ask a question (which is in the knowledge base).
The system should find the relevant article / answer for the question. - API Integration
The system should have an API for easy interaction with my other systems.
In order to achieve this, we will feed in some wikipedia articles and then ask questions:
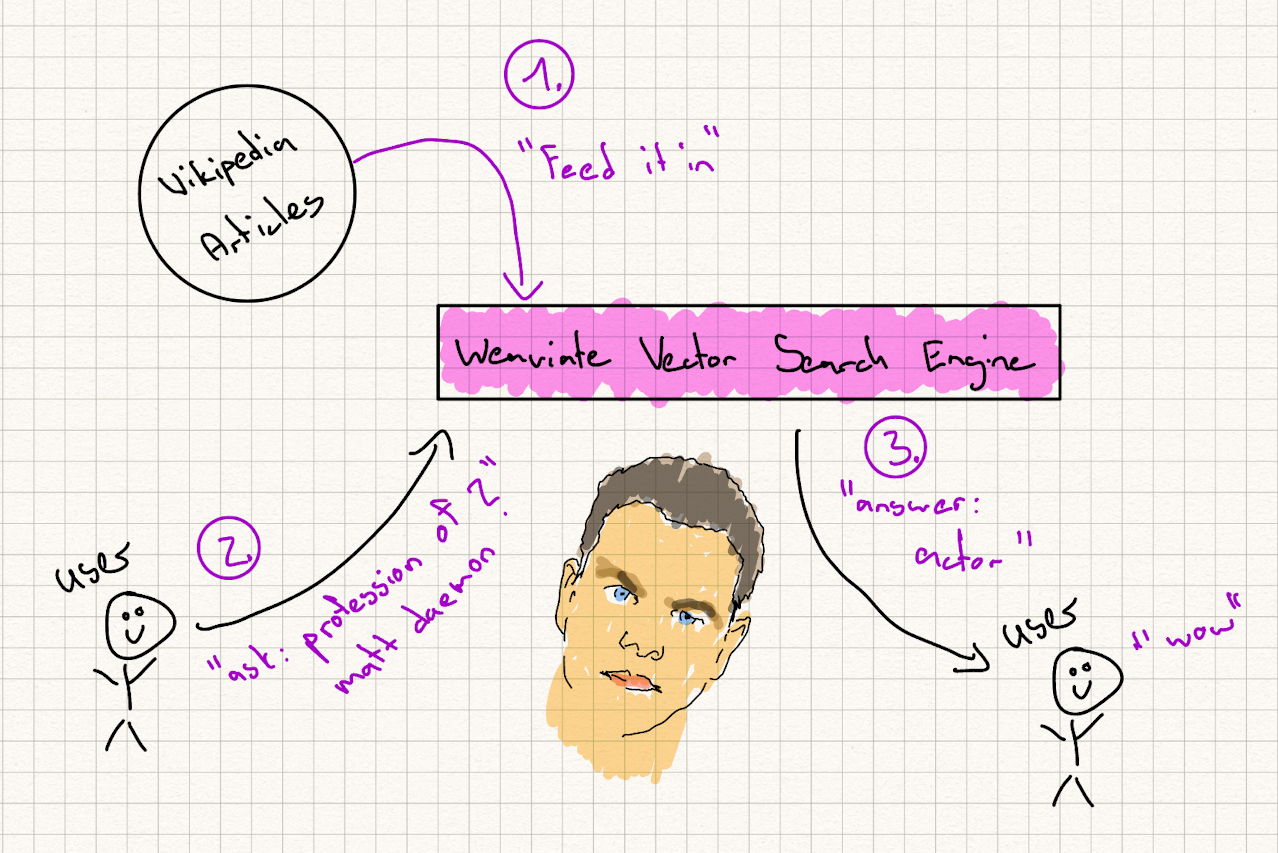
Kubernetes Deployment
I like to run Weaviate on my test server (on premise), aka a node in my kubernetes cluster. Here are some important points to take into consideration before deployment.
If you would like a blog post on how to bootstrap a kubernetes cluster in house for running workloads and testing, let us know.
Disk Space
To address the storage requirements of pre-trained language models, I increased the disk space of a designated Kubernetes node. Employing node taints, I ensured that the deployment of Weaviate is directed to this specifically configured node. We have two significant components: the Sentence Transformer Image and the QnA Model, each ranging from 5 to 10 GB in size.


Graphics Card (GPU)
Utilizing GPUs can significantly enhance the performance of machine learning models, with potential speedups of up to 10 times. Regrettably, our Kubernetes node lacks a GPU, necessitating the use of CPU-only resources for testing purposes.
Our deployment strategy relies on ArgoCD and a Kustomization configuration for managing deployments across the Kubernetes cluster. Below, you'll find the deployment chart for reference.
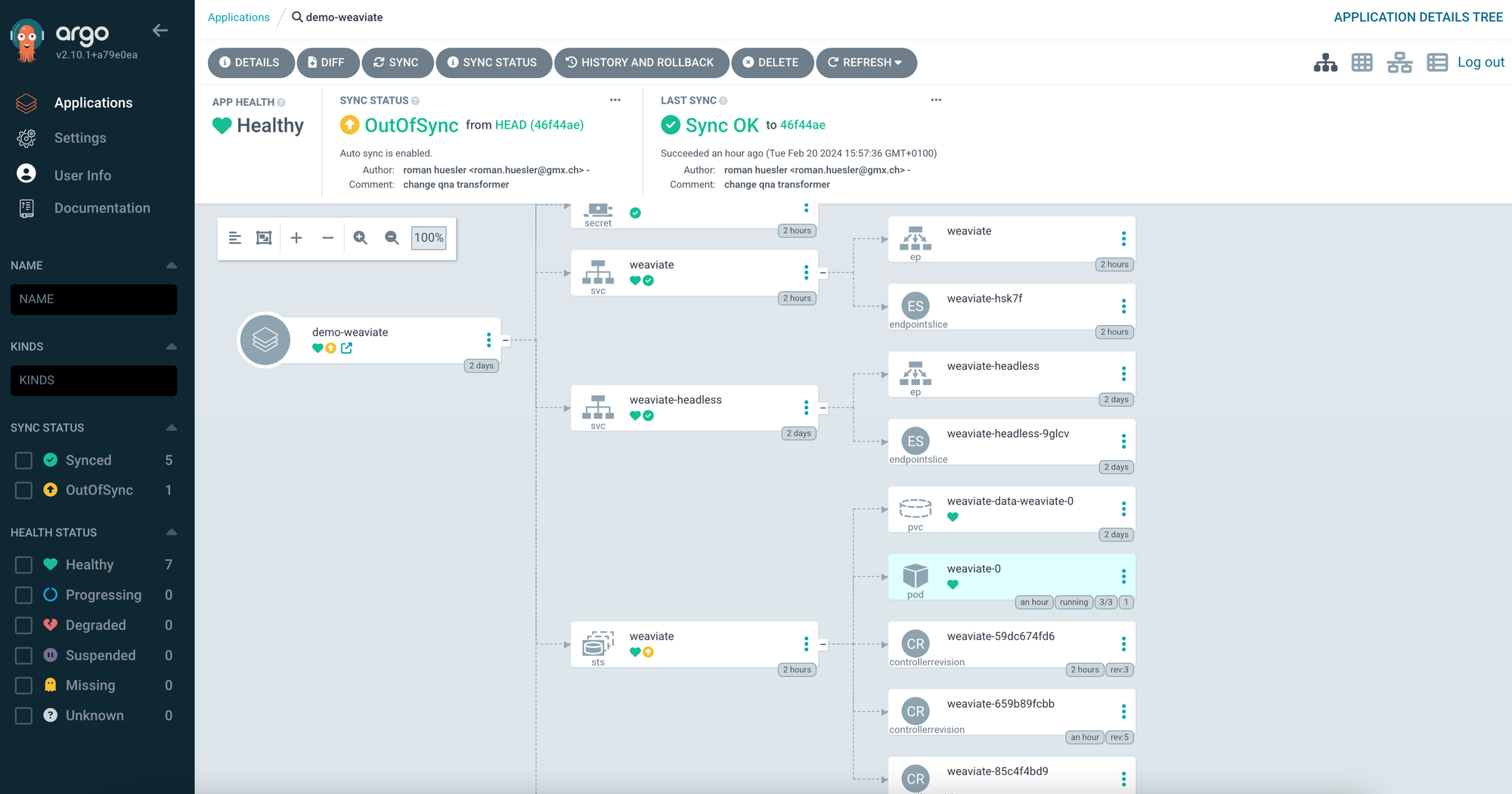
The Kubernetes Statefulset of Weaviate was properly deployed and we can see a pod that runs 3 containers for weaviate, text-2-vector transformer and qna-transformer.
It is now ready for usage and we can start to run tests.
Schema Creation
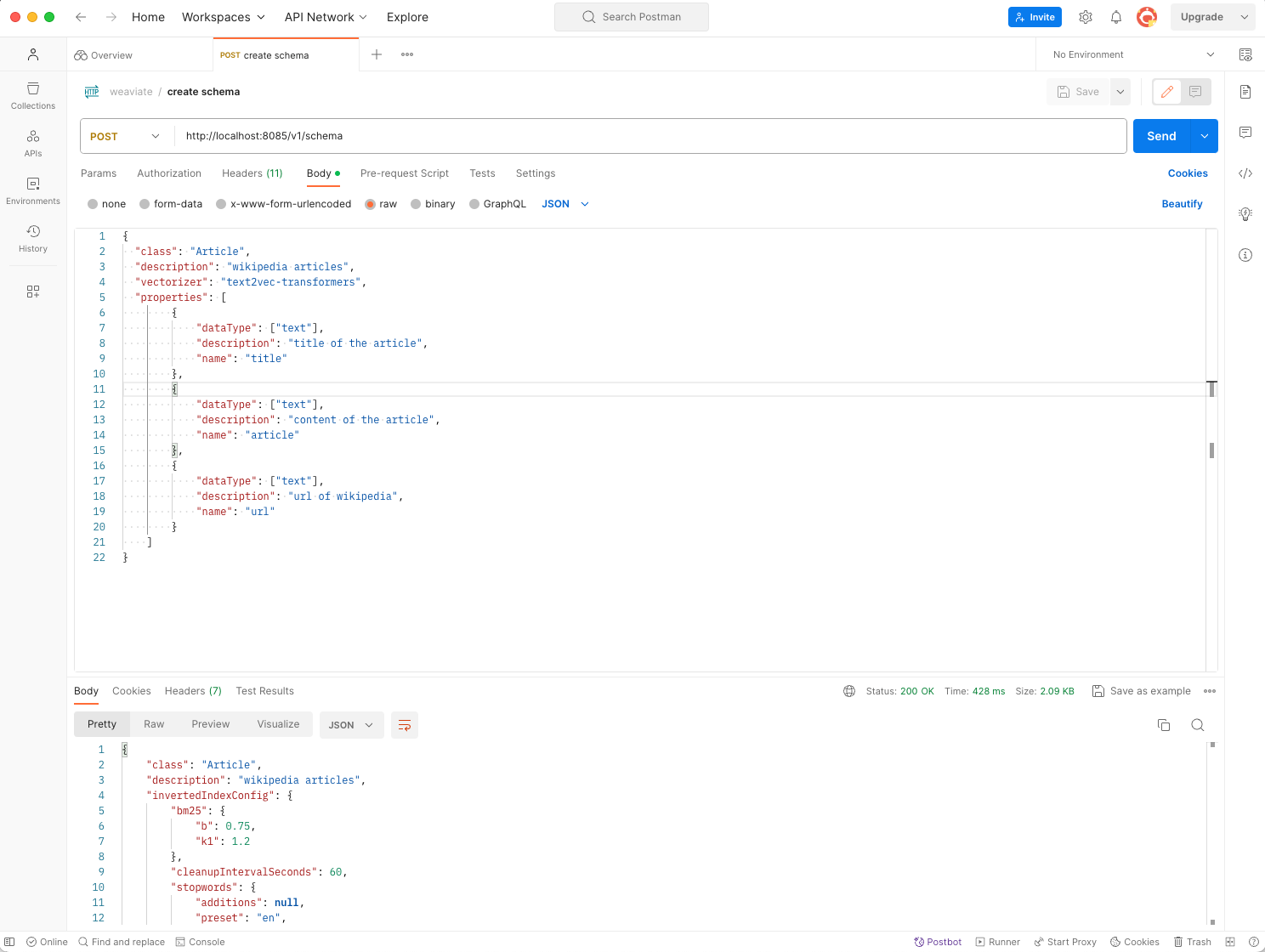
While reviewing the documentation and quick start guides for Weaviate (link - Weaviate quick start guide), I discovered the initial step involves creating a "schema". Our objective is to construct a knowledge base containing Wikipedia articles as test data. To facilitate this, I forwarded Port 8085 of the Weaviate Pod to my local machine. Utilizing Postman (http://localhost:8085/v1/schema), I proceeded to establish a basic schema comprising three properties.
- title
title of the wikipedia article - article
content of the wikipedia article - url
url to the wikipedia article
Data Onboarding
To evaluate Weaviate, I imported data/articles from Wikipedia. An effective test scenario involves uploading an article about "Matt Damon" and subsequently querying for his profession: "what is the profession of matt daemon?". This test is particularly meaningful given that the Wikipedia article on "Matt Damon" does not explicitly mention the term "profession" (as of the time of writing).
I utilized Wikipedia's "random article" feature to select articles for indexing. By copying the text from these articles via the "edit" function, I indexed approximately 60 articles in this manner.
Upon preparing a Postman Post Query to send/index data to Weaviate, I observed a notable delay in indexing. This delay was primarily due to Weaviate's process of transforming sentences into vectors, which consumes significant computational resources. As previously mentioned, my Kubernetes node lacks GPU capabilities. I attempted the same setup on hyperscalers such as GKE and AKS, but encountered a substantial scarcity of GPUs as of the current date.
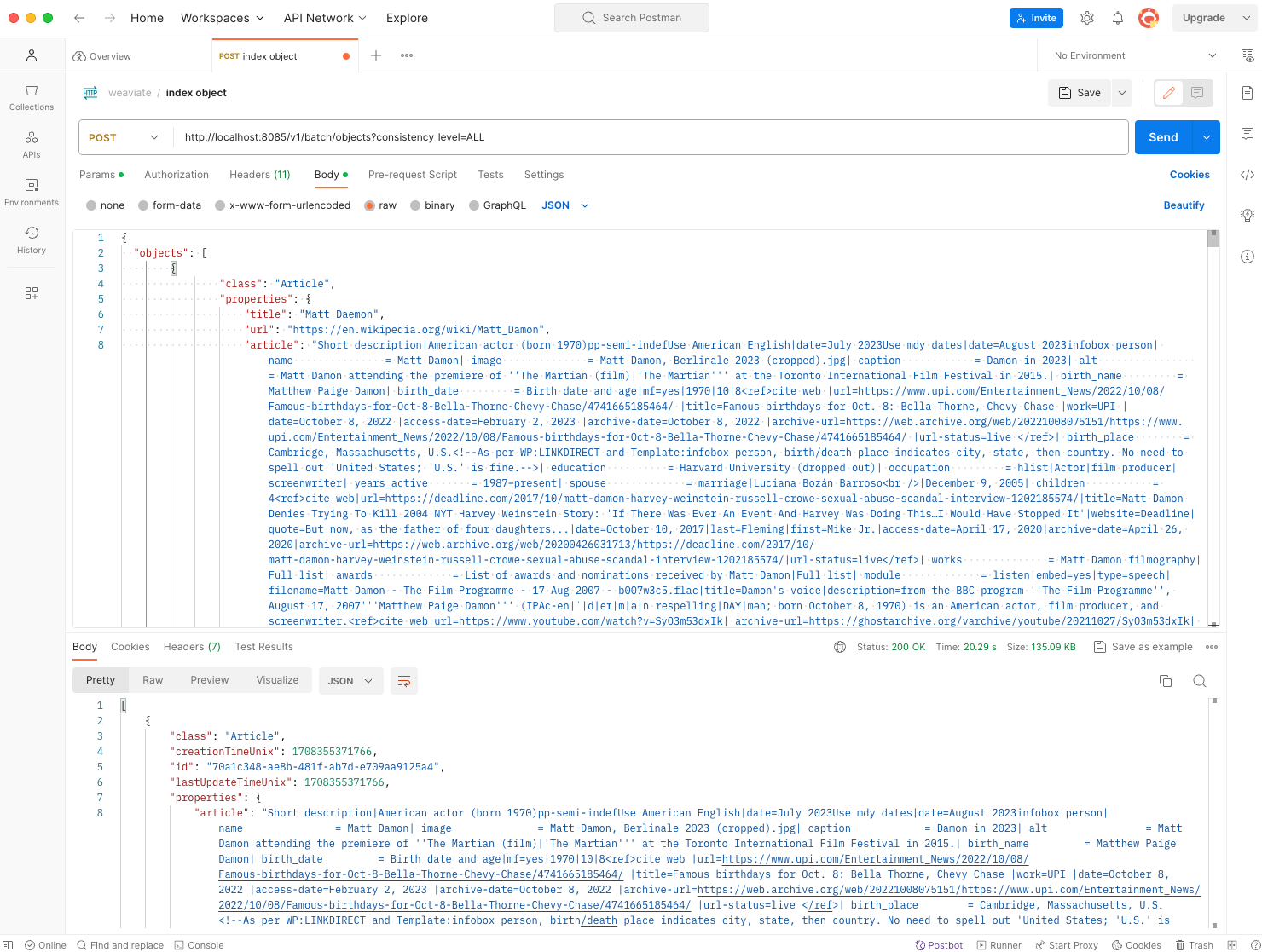
Using an API that returns all indexed objects, I could verify that the object was indexed. In the same manner I have continued and indexed around 60 random wikipedia articles.
# weaviate - query all indexed objects
curl http://localhost:8085/v1/objects?class=Article&&limit=100Great, now it is time to run some queries!
Basic Searching
At this point, I've tried some basic search queries, just to see wether weaviate is working properly. When searching for "matt", it is returning the indexed object with a certainty of around 70%.
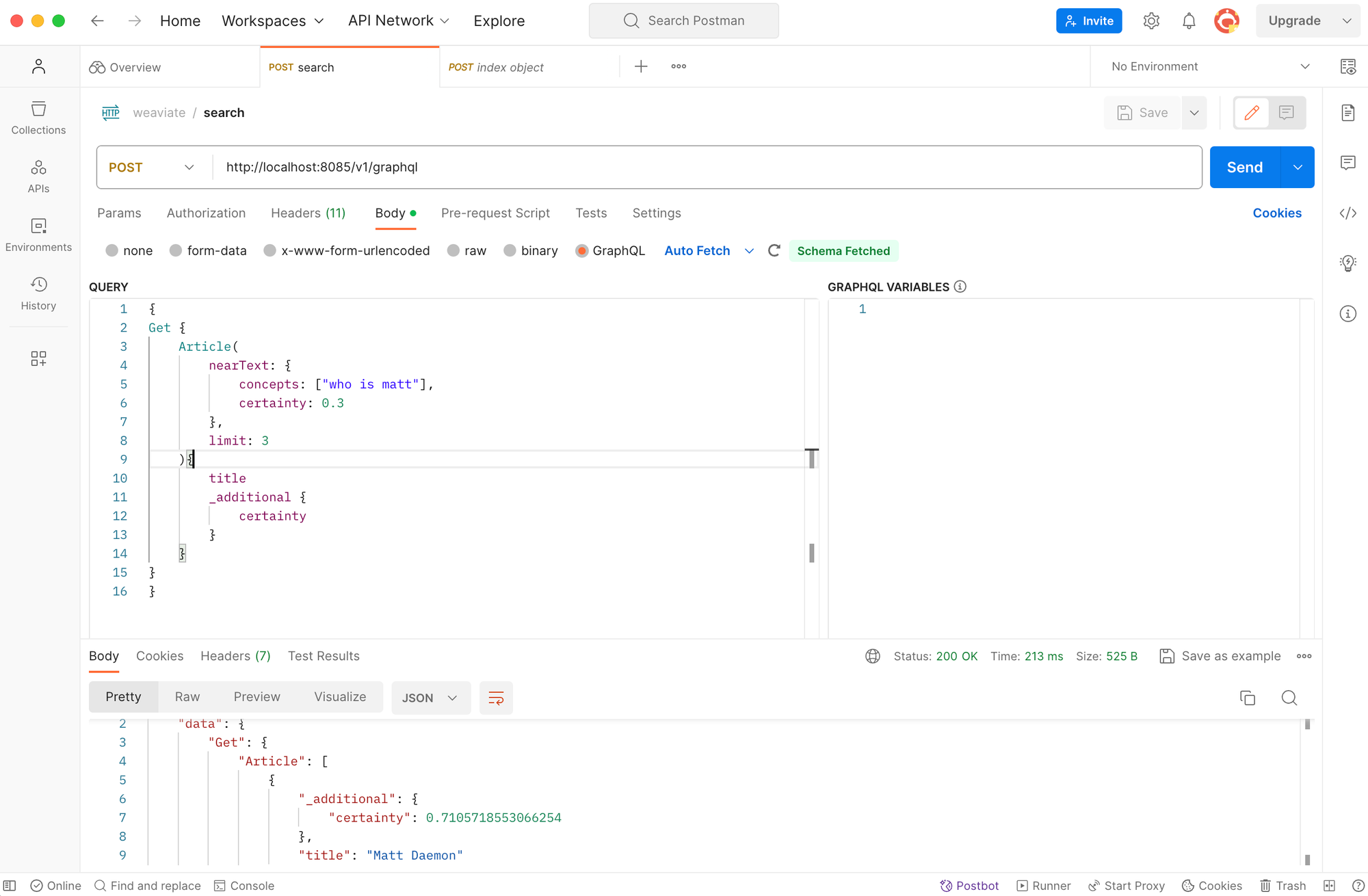
Here is the GraphQL Query that I have used.
{
Get {
Article(
nearText: {
concepts: ["who is matt"],
certainty: 0.3
},
limit: 3
){
title
_additional {
certainty
}
}
}
}Weaviate - GraphQL Query for Basic Searching
Advanced Search - QnA Transformer
Now let us try to extract answers from our indexed wikipedia articles. I thought of some questions that I could ask about "matt daemon", the article that we have indexed before. "What is the profession of matt daemon?" would be a good question, because the article does not even contain the word "profession".
As a QnA-Transformer Model, I've planned to use bert-large-uncased-whole-word-masking-finetuned-squad before (a model with 335 million params). But during testing, I ran into problems with timeouts. The model performance was just too slow on my kubernetes node without GPU. So I decided to use another model: distilbert-base-uncased-distilled-squad which "only" has 66.4 million params.
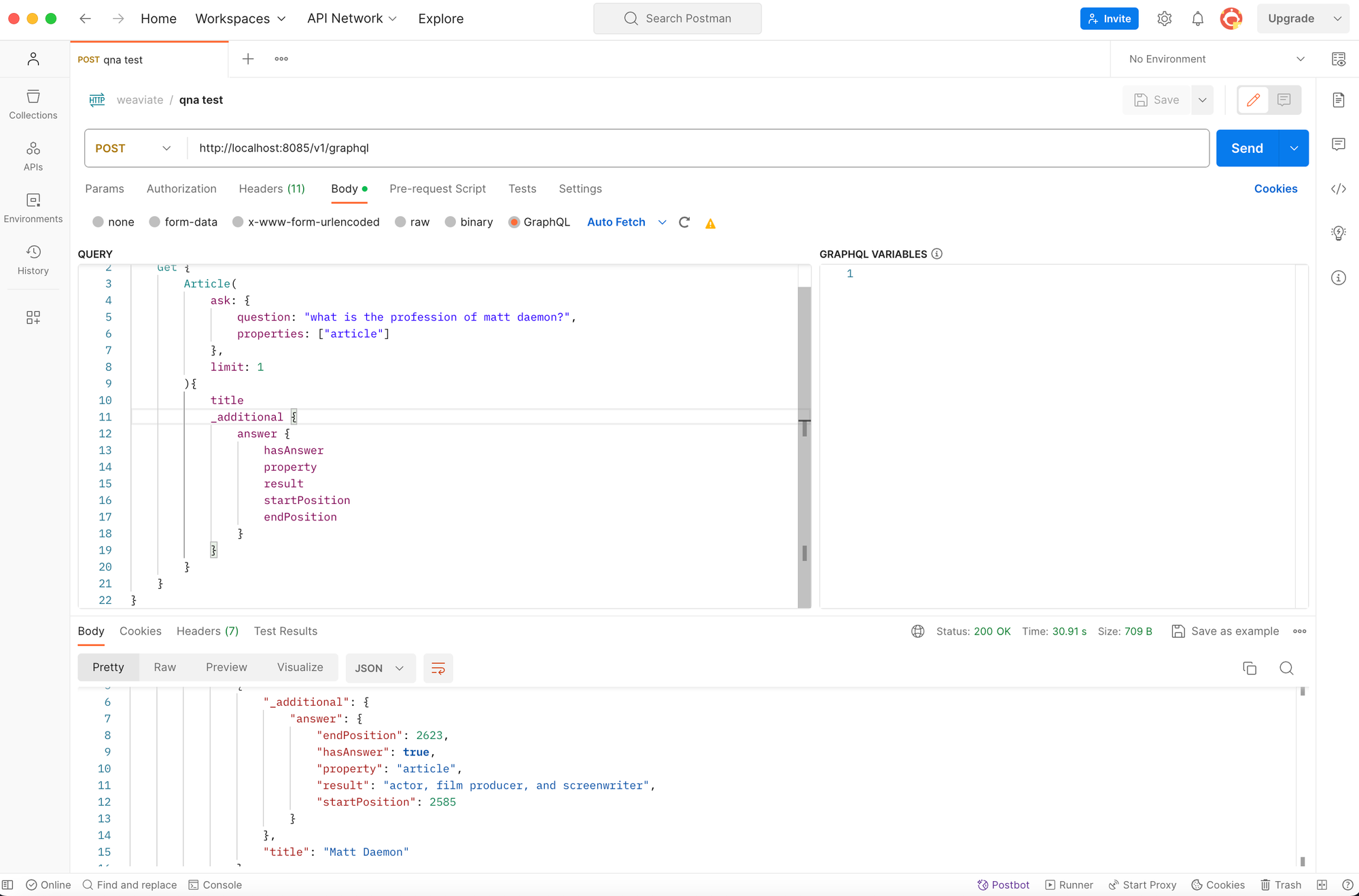
{
Get {
Article(
ask: {
question: "what is the profession of matt daemon?",
properties: ["article"]
},
limit: 1
){
title
_additional {
answer {
hasAnswer
property
result
startPosition
endPosition
}
}
}
}
}Weaviate GraphQL Query - QnA Searching
It found that matt daemon is an "actor, film producer and screenwriter".
Very good - that seems about right!
Conclusion
These are the goals, that I have definied when I started to have a closer look at weaviate. I think we have now achieved all of them.
- AI on premise
Have an AI that can operate locally on premise. - Knowledge Base
It should be able to interact with text data (i.e. a knowledge base) - Question, Answer
I like to be able to ask a question (which is in the knowledge base).
The system should find the relevant article and answer for the question. - API Integration
The system should have an API for easy interaction with my other systems.
Creating a UI Frontend for Querying
We might find it beneficial to develop our own UI or web frontend for facilitating interaction with Weaviate. This would simplify the process of executing search queries. Please inform us if you would be interested in a blog post discussing this topic further.
Until next time
Although I possess a solid understanding of neural networks in the meantime, natural language processing (NLP), tokenization and embedding models, it is nevertheless fascinating to me to see the possibilities and use cases of AI and vector search engines.
I hope this blog post was also interesting for you and until next time.
Links, Ressources