AI On Premise - Part 1 Theory
Weaviate for AI-Powered Knowledge Management On Premise. Discover how Weaviate, an AI-powered vector search engine, revolutionizes knowledge management.


Feed all your sensitive data into an AI knowledge base, that can answer your questions? No problem - as long it is running in house.
opensight.ch - roman hüsler
The LLMs are the latest rage, a big step in digitalization and a disruptive technology. It is not without reason that many companies ask themselves how can I use the technology in my company. Companies' sensitive data usually cannot be easily sent to a cloud-based AI such as chatgpt for evaluation. Companies therefore often ask themselves how AI solutions can be used internally and securely.
AI has diverse applications across various tasks. In this blog, our current focus is not on LLMs. However, if you express interest in this topic, please let us know. Instead, we delve into a related area of AI: natural language processing (NLP) and the establishment of an "on-premise AI-powered" knowledge base. This involves integrating with your local Knowledge Base, such as Confluence, to develop a question-answer AI system.
Today we take a look at Weaviate, an AI-powered vector search engine that works with pre-trained language models and can be operated internally / on premise.
opensight.ch - roman hüsler
Like many IT professionals, I too am acquiring knowledge in this field. I assume that many readers of this blog are in a similar position, which is likely how they found this post. This implies that being an AI specialist is not a prerequisite for understanding the content of this blog post.
Content
The Big Goal - AI On Premise
Let's set the stage for this blog series. We would like to achieve:
- AI on premise
have an AI that can operate locally on premise - knowledge base
it should be able to interact with text data (i.e. a knowledge base) - question, answer
I like to be able to ask a question (which is in the knowledge base). It should find the relevant article and answer the question - api integration
It should have an API for easy interaction with my other systems
What is a vector search engine
"Weaviate is an open-source, cloud-native vector database that allows you to store and query vectorized data. It is designed for handling high-dimensional data and is particularly useful for machine learning applications. Weaviate uses a schema-based approach and supports semantic vectorization, making it efficient for searching and retrieving complex data structures. You can interact with Weaviate using its RESTful API, making it suitable for integration with various programming languages, including Python, JavaScript, C#, and Go. To get started, you can explore the documentation and use code snippets provided in your preferred programming language."
traditional search engine
-------------------------
indexed_sentences:
- "i have seen a giraffe in the zoo"
- "in the wildlife park, i've seen an elephant yesterday"
vector search engine
-------------------------
indexes_sentences:
- [0.34837, 0.84732, ...]
- [0.39872, ...]
In a traditional search engine, content is indexed and stored so that it can be quickly searched through. For example, if you index the phrase "I have seen a giraffe in the zoo," you can easily find this item by searching for "zoo" However, you won't find the sentence (above) containing the word "elephant" because it does not include the word "zoo."
Vector Search Engines, on the other hand, learn which words are related to each other and are relevant to the current context. Their index operates with vectorized text, represented as numerical values. Training AI models to convert text into numbers requires significant computational resources and a large corpus of sample text. This is why we can utilize pre-trained models with our vector search engine (Weaviate).
For example, if you were to search for "Which animals could I meet in the zoo?" The magic of a vector search engine lies in its ability to potentially find both indexed items (above) because it has been trained on a diverse range of text samples. It understands that the words "zoo," "animal," "elephant," and "giraffe" are closely related in terms of context. Let's dive deeper on neural network natural language processing and see how this is possible.
Background Information - Neural Network NLP
How neural networks "understand" text and language with natural language processing (NLP) - in a nutshell.
Step 1 - Turning Text into Numbers
Text must be converted into numbers so that neural networks can process it. In essence, this process is straightforward. Simply input a lot of text and assign a number to each word. The result is a dictionary of fixed size containing the most common words. If you intend to work with text-based data alongside AI, it is essential to convert the text into numerical representations.
Simple Example Dictionary with just 4 words
"the dog ate the wiener"
[0, 1, 2, 0, 3]
0: the
1: dog
2: ate
3: wienerStep 2 - Create Embeddings
The neural network has to learn word embeddings, so it learns which words are related to each other. This is done by training with a lot of text samples and the dictionary that has been created (step 1).
text sample sentence:
"the dog ate the ___" (correct answer: "wiener")
possible answer:
"pancakes"
wrong answer:
"window"During training, the neural network creates a high-dimensional vector embedding space to learn the relationships between words. It does this by taking a text sample and removing a random word, then attempting to predict the missing word based on context. Through exposure to numerous text samples, the network learns these relationships.
For instance, it might encounter phrases like "a dog ate a wiener," but it won't encounter phrases like "a dog ate a window." Therefore, even though "window" and "wiener" may be close together in the dictionary, they are unrelated in context.
This training requires a lot of text samples and compute resources, which is why we can use Pretrained Sentence and QNA Transformers with Weaviate.
opensight.ch - roman hüsler
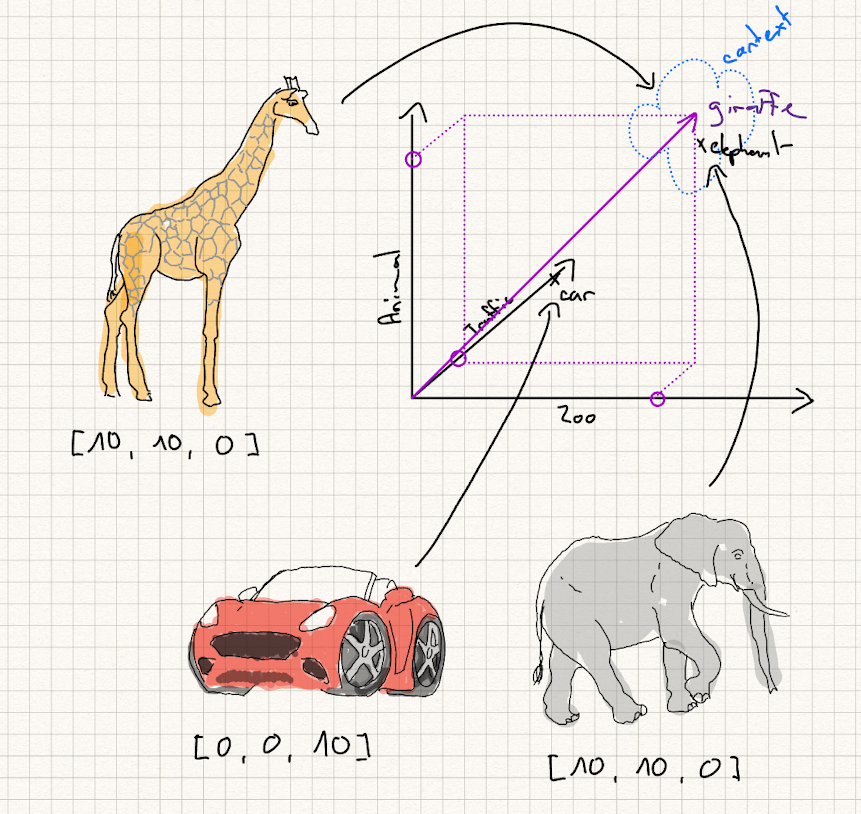
As another example that shows how I personally think about vector embeddings. Consider 3 words: "elephant", "giraffe", "car". Consider an NLP Embedding Layer with just 3 dimensions which represent:
dimension-1 zoo: "how much has something to do with "zoo"
dimension-2 animal: "how much has something to do with "animal"
dimension-3 traffic: "how much has something to do with "traffic"
Now, "giraffe" and "elephant" would rank highly on dimension-1 and dimension-2, while ranking low on dimension-3. They share a similar context on two dimensions. The word "car" ranks highly on dimension-3, so it is not located "near" the other two words.
This is just an example. In a real world model, there can be thousands of dimensions and you don't know what factor they represent. The dimensions are learned automatically by a neural network by looking at a lot of text samples and adjusting its weights. If you like to dive deeper on how that works, I can recommend to you the following course:
Tensorflow - Zero to Mastery
Weaviate Sentence Transformers
Weaviate is a vector search engine - it stores / indexes our content as numbers. We use a pretrained sentence transformer from Hugging Face / Semi Technologies to achieve this task. Here is a list of possible transformers that you could use:
link - weaviate text2vec-transformers
There is also the possibility to plugin cloud-based transformers (like OpenAI) using an API key or even train and plug your own sentence transformer.
The sentence transformer we use has been trained on 215M (question, answer) pairs from diverse sources (multilingual) and uses a 384 dimensional dense vector space. This means each sentence will be turned into an 384 dimendianal vector when indexing. It was designed for semantic search so that is ideal for our purpose (finding the matching knowledge base article for a given search query).
The Vectorizer Model on Hugging Face:
semitechnologies/transformers-inference:sentence-transformers-multi-qa-MiniLM-L6-cos-v1
In the next part of this blog series, we will plug this transformer in to weaviate
Weaviate QnA Transformers
We also will try out a qna transformer. This AI Transformer is relevant in order to extract the correct answer for our search query out of the knowledge base article.
Here is the page from weaviate on Question and Answer Transformers:
Weaviate - QnA Transformers
As a qna transformer we will use:
semitechnologies/qna-transformers:bert-large-uncased-whole-word-masking-finetuned-squad
Conclusion
That concludes the theory part. In the next section, we will put everything into practice. Subscribe to our blog to be onboard for the next part of this blog series:
AI On Premise - Part 2 In Practice