Azure AI - Automatically capture form data with artificial intelligence
Revolutionize your expense recording process effortlessly using Microsoft Form Recognizer, an AI-powered document extraction service. This Azure-based solution seamlessly recognizes, extracts, and labels data from scanned or photographed receipts, converting them into JSON format.


Microsoft Form Regognizer
Have you ever heard of “Microsoft Form Recognizer”? It is the Microsoft AI-powered Document Extraction Service, which “understands your documents”. That sounds pretty good so far. We have taken a closer look at the service for you.
AI or artificial intelligence is a technology that will lead to disruptive changes / upheavals in the next few years and which you are definitely not hearing about for the first time. Major manufacturers like Microsoft are striving to make these new technologies available to a broad user base in a way that no longer requires a doctorate to operate them, as you will see in this blog post.
The Microsoft Form Recognizer is an Artificial Intelligence Service (AI) that recognizes, extracts, labels and outputs data from your scanned or photographed documents in JSON format.
Roman Hüsler - opensight.ch
Of course, the service can process all different types of documents (e.g. photos, scanned PDF files). For the purpose of this blog post, we focused on “expenses” (i.e. receipts). The goal is to be able to take a photo of a receipt with your cell phone and the rest happens automatically.
expense recording in a few simple steps
In a few simple steps, we now use artificial intelligence to automatically recognize the price and date on photographed receipts.
Infrastructure
First, a resource group is created in Azure to contain the necessary services. For this test, a blob storage is created in the resource group to store the data, and the “Microsoft Form Recognizer” Service created.
Prepare Samples
The first step is to digitize the documents to be processed in some form. Since we are using receipts as input in this example, I took some photos of them with my phone and uploaded them to Azure Blob Storage. At least 5 samples are necessary / 5 photographed receipts so that the artificial intelligence can be trained. It is of course an advantage to be able to use more samples, but for this test the 5 are enough for us.
Labeling and training of artificial intelligence
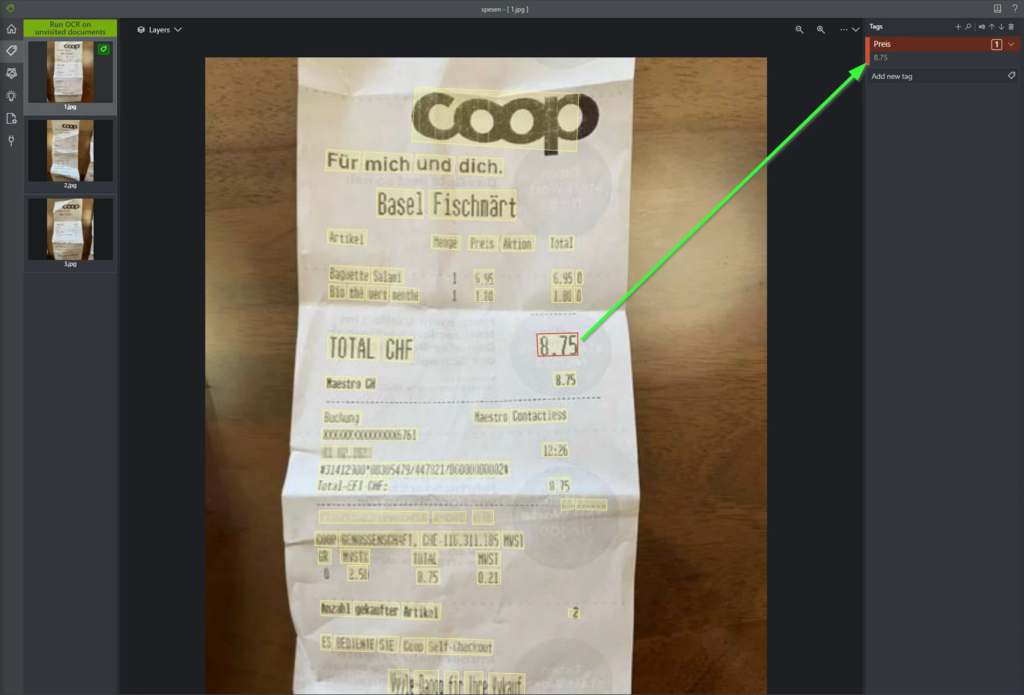
docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltooldocker run -it -p 3000:80mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool eula=acceptYou can install the labeling tool (picture above) on a Docker host. The labeling tool reads the uploaded data from the Azure Blob storage and recognizes the text (OCR). You can then click on the text you want on the receipt and add a label. E.g. “Price” / “Date”. Now repeat this for all uploaded samples.
Artificial intelligence training
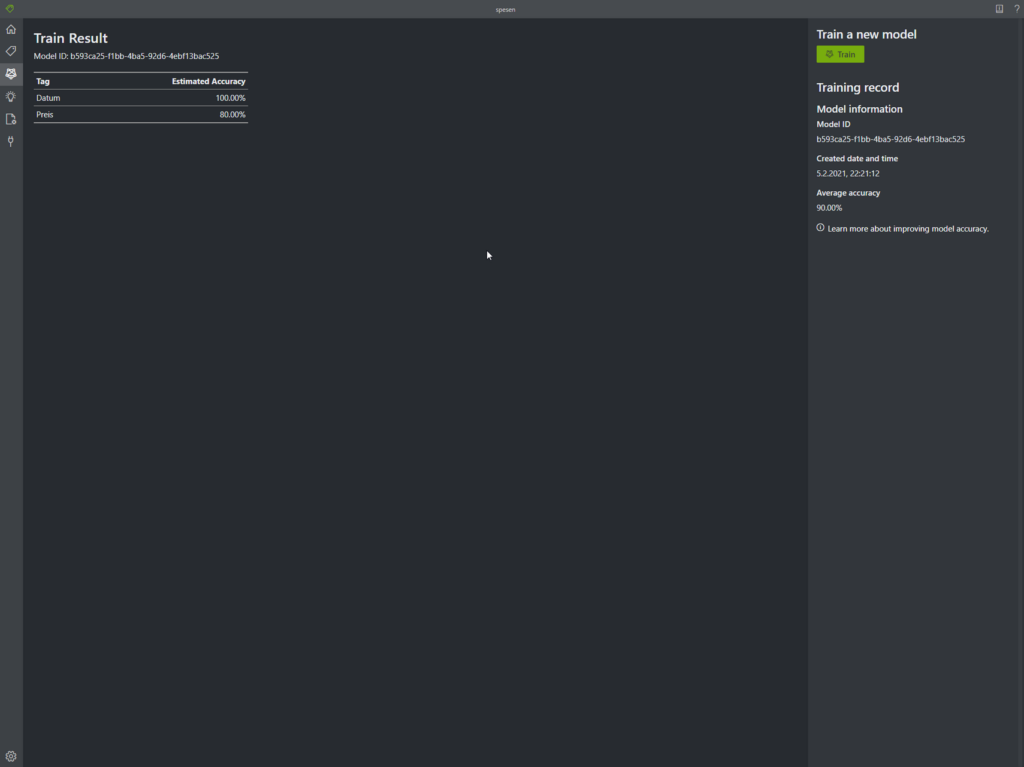
In the Training tab we simply click on “Train” so that the artificial intelligence is now trained using our uploaded samples. Under Estimated Accuracy we can directly see the expected accuracy with which the AI will deliver results. In our case, 80% is not entirely satisfactory, but we only uploaded 5 samples for testing.
Production
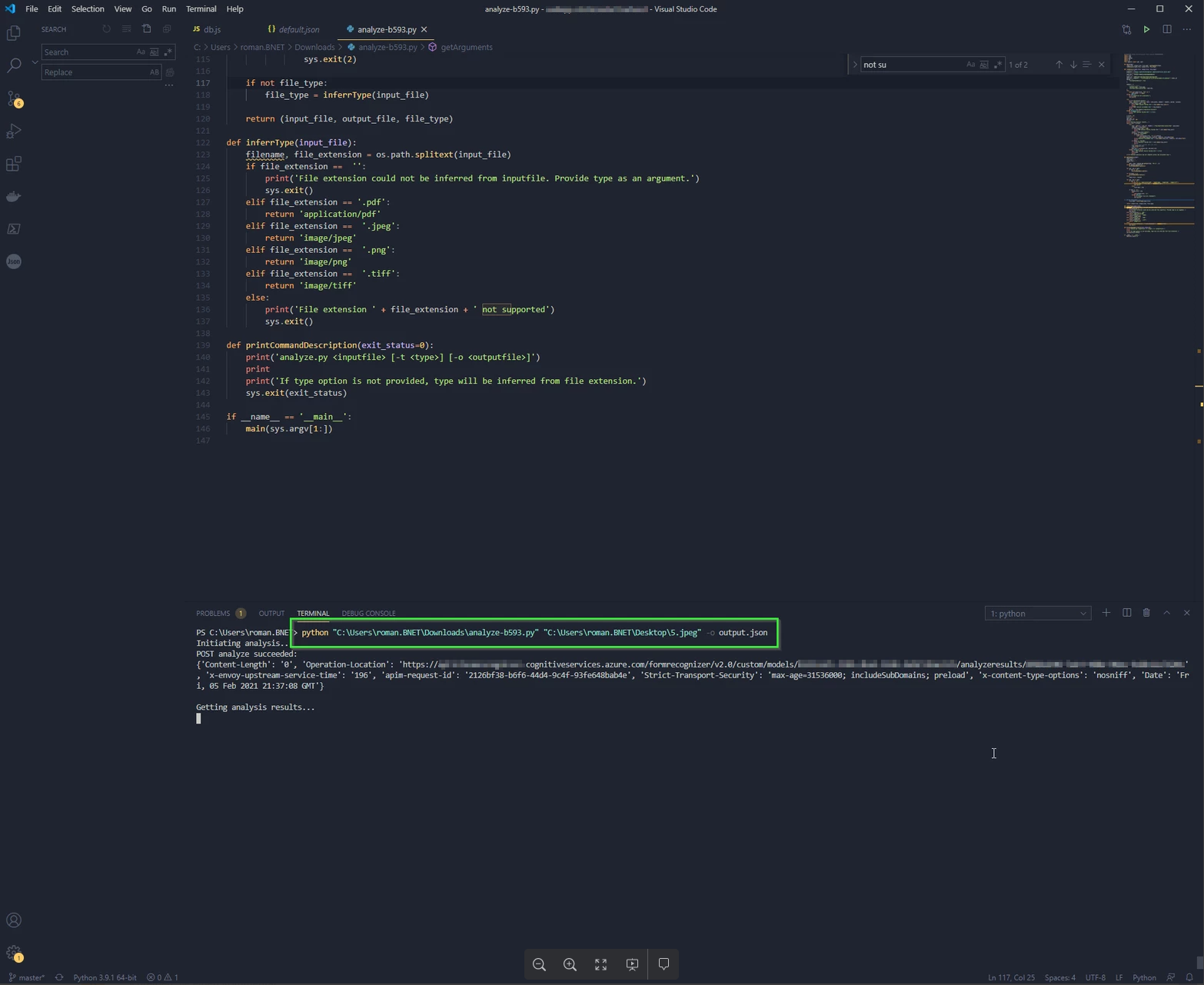
With a Python script we can now process any additional receipts and the fields “Price” and “Date” have it read out. The defined fields are output as output (date / price), as well as all the remaining recognized text in another JSON attribute. This is absolutely ideal if you want to save the results to a schemaless database or Elasticsearch so you can quickly find the forms / receipts later.
Of course, the process could now also be integrated into a backend API where you can upload the expenses or into a “Power App” so that you can simply take a photo of the expense slips with your cell phone.
Pricing
You can have 500 pages scanned/processed free of charge per month. After that, you need a paid model for 50 francs per 1000 pages. Details can be found on the Microsoft Homepage.